
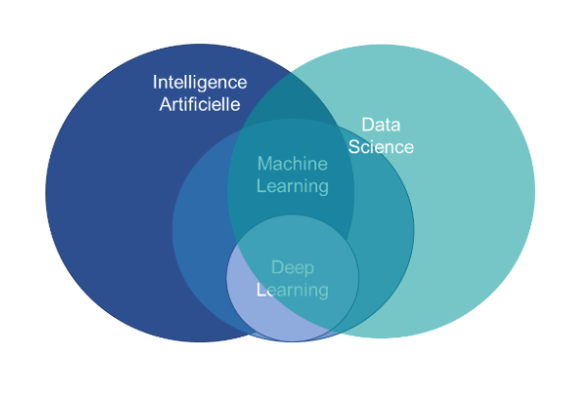
Les techniques de la Data Science, de l’Intelligence Artificielle, du Machine Learning et du Deep Learning se croisent, s’alimentent et poursuivent parfois le même objectif. Ces démarches restent néanmoins des disciplines à part entière, chacune d’elles se matérialisant par des outils et réalisations dédiés :
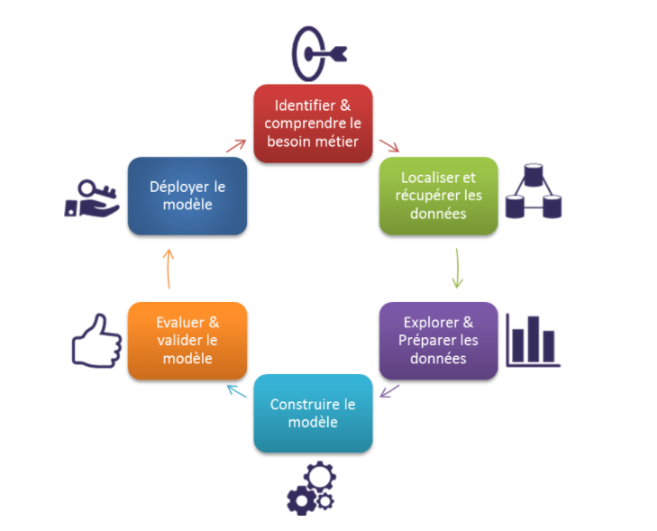
Cycle de vie de votre projet Data Transformation :
La première étape consiste à comprendre le besoin métier, les différentes spécifications, exigences et priorités.
Ensuite, les données doivent être collectées, extraites à partir de différentes sources. Il s’agit ensuite de les entreposer dans une DataLake, de les nettoyer, de les transformer afin qu’elles puissent être analysées. L’étape suivante est celle du traitement des données, par le biais du Data Mining (forage de données), du clustering, de la classification ou de la modélisation.
Les données sont ensuite analysées à l’aide de techniques comme l’analyse prédictive, la régression ou le text mining. Enfin, la dernière étape consiste à communiquer les informations dégagées par le biais du reporting, du dashboarding ou de la Data Visualization.
Afin de mener à bien un projet Data Intelligence, il est très important de suivre toutes les étapes du cycle de vie afin d’assurer le bon fonctionnement du projet. Les étapes à suivre pour réussir un projet de Data Science sont décrites dans le graphique ci-dessous :
Le Machine Learning :
Le Machine Learning est un système qui fonctionne à partir d’algorithmes qui, alimentés de données, tendent à apprendre et à s’améliorer automatiquement. Les processus d’apprentissage et d’amélioration continue se font à partir de l’expérience et non pas grâce à une programmation.
Ainsi, l’apprentissage consiste à traiter des observations ou des données (des exemples, une expérience ou des instructions) dans le but de rechercher des modèles permettant la mise en place de prédictions et la prises de décisions.
Les algorithmes de Machine Learning s’exécutent selon différents apprentissages et produisent des modèles d’algorithmes spécifiques. Ci-dessous, nous détaillions les 3 grandes familles d’apprentissage :
L’apprentissage supervisé : Les algorithmes de Machine Learning supervisés peuvent appliquer ce qui a été appris dans le passé à de nouvelles données en utilisant des exemples étiquetés pour prédire des événements futurs. Cette méthodologie d’apprentissage permet la construction d’une fonction de prédiction à partir d’exemples.
L’apprentissage non supervisé : Ses algorithmes apprennent à partir de données d’essai qui n’ont pas été étiquetées, classées ou catégorisées. Cette approche permet de trouver une structure dans les données, comme le regroupement ou le clustering.
L’apprentissage semi-supervisé : Les algorithmes de Machine Learning semi-supervisés se situent entre l’apprentissage supervisé et non supervisé. Ils utilisent à la fois des données étiquetées et non étiquetées pour l’apprentissage.
Le Machine Learning est utilisé dans différents secteurs pour répondre à diverses problématiques. A titre d’exemple, grâce à cette discipline, il devient aisé d’identifier des opportunités d’investissement en calibrant les systèmes de négociation, de proposer des recommandations précises et personnalisées aux consommateurs, ou encore de lutter contre la fraude.
Le machine learning avec la suite Elasticsearch https://www.elastic.co/
Elasticsearch est un moteur de recherche et une base de données de type NoSQL, open source, conçu pour stocker, interroger et analyser de grandes quantités de données rapidement et de manière distribuée. Il fait partie de ce qu’on appelle la suite ELK, qui comprend Elasticsearch, Logstash et Kibana. Il est largement utilisé pour la recherche et l’analyse de données dans divers domaines tels que la recherche sur le web, l’analyse des journaux, la surveillance des infrastructures, la recherche en texte intégral, l’analyse des données en temps réel, etc.
Les principales caractéristiques d’Elasticsearch comprennent :
- Distribution et évolutivité : Il est conçu pour fonctionner de manière distribuée sur un cluster de nœuds, permettant de gérer de grandes quantités de données tout en assurant la disponibilité et les performances.
- Recherche en texte intégral : Elasticsearch utilise une recherche en texte intégral qui lui permet d’indexer et de rechercher des données textuelles complexes très rapidement.
- Performances élevées : Grâce à son architecture distribuée et à ses fonctionnalités de recherche optimisées, Elasticsearch offre des performances élevées pour les requêtes et les analyses de données, même sur de vastes ensembles de données.
- API RESTful : Elasticsearch expose une API RESTful permettant aux développeurs d’interagir facilement avec le système pour effectuer des opérations d’indexation, de recherche et d’administration.
- Analyse et agrégation de données :Il propose des capacités d’agrégation et d’analyse avancées permettant de réaliser des agrégations, des statistiques, des regroupements et des analyses de données complexes.
- Extensibilité et intégration : Il peut être étendu via des plugins pour répondre à des besoins spécifiques et s’intégrer à d’autres outils et systèmes.
En résumé, Elasticsearch est une technologie puissante et flexible largement utilisée pour la recherche et l’analyse de données, offrant des fonctionnalités avancées pour stocker, interroger et analyser efficacement de grandes quantités de données.
Dans ELK, la puissance de Machine Learning est intégrée dans Elasticsearch et Kibana.
En d’autres termes, si les données sont stockées dans Elasticsearch, elles sont prêtes pour le Machine Learning. La Suite Elastic traite les données au moment de l’ingestion.
D’autres outils sont intégrés comme Data Visualizer qui servent à la visualisation et la compréhension des données.
Le machine learning non supervisé signé Elastic aide à trouver des modèles dans les données. Il est possible de modéliser les séries temporelles pour détecter les anomalies dans les données actuelles, et prévoir les tendances grâce aux données d’historique.
Ensuite il est possible d’utiliser la détection des anomalies pour examiner les points de données qui se détachent du reste.
ELK offre une expérience de workflow intégrale sur un large panel de cas d’utilisation, où l’exécution des tâches de régression, de classification et de détection des aberrations sur les données ne nécessite pas le développement d’algorithmes de machine learning.
En partant des transformations continues que subit un index de logs d’application, il est possible d’élaborer une vue des activités centrée sur l’utilisateur et mettre au point un modèle de détection des fraudes à l’aide de la classification.
Ensuite, avec le processeur d’ingestion par inférence, l’application des modèles aux données entrantes est au moment de l’ingestion.
Ce qui fait que la création de tâches de machine learning est très simple avec ELK.